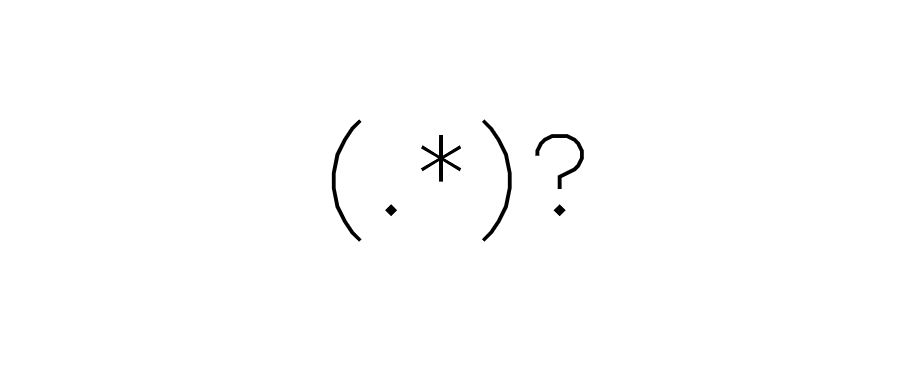
(?i)(?'<'A_Brief_Intoduction_to>^(Re(gular Expressions?$|[gexp]{3,4}$|[gexp].*?(?<=x)es$)))
If the title of this blog post is confusing to you, you’re in the right place! That jumbled mess of text is a type of formal language (or more precisely, a regular language) called Regular Expression. A regular expression, also known as regex or regexp, is a logical sequence of characters that are used to locate, manage, and define search patterns. But what does that really mean?
What is Regex?
Let’s say for example you have a 100-page document. Somewhere within that document there is a phone number you need. Since you’re not sure what the number is, you can’t exactly search the document for it. But are you really going to waste the next hour or two of your time searching through this document to find one phone number? With regex, you don’t have to!
This simple regex will go through an entire document in a fraction of a second, and match all phone numbers in “### ### ####” format:
\d+\s\d+\s\d+
In order to explain how this works, there are two basic regex concepts we need to understand. These concepts are “Character Classes” and “Quantifiers”.
Character Class
A Character Class is a special notation used for matching types of characters. The most common character classes are:
- \d - Will match a single digit from 0-9
- \w - Will match a single word character. A word character can be any letter or number, as well an underscore
- \s - Will match a single space, tab, or newline character
Quantifier
A Quantifier can be added to the end of a character class to specify how many times you would like to repeat the character class to define a match. Regex quantifiers include the following:
- * - Matches zero or more times
- + - Matches one or more times
- ? - Matches zero or one time
- {x} - Matches x times
- {x,} - Matches at least x times
- {x,z} - Matches from x to z times
#Try it Out Looking back to the regex from earlier, we should now be able to break down how it works:
\d+ ------- matches one or more digits
\s --------- matches one space
\d+ ------- matches one or more digits
\s --------- matches one space
\d+ ------- matches one or more digits
Now, although this regex works, it works a little too well. It’s very easy to match characters with regex, the hard part is not matching what you don’t intend to. Because we weren’t very precise with our regex, we would match “1 1 12”, as well as “111 111 1111”. This is because we used the ‘+’ quantifier, where we should have used the ‘{x}’ quantifier.
d{3}\s\d{3}\s\d{4}
This regex will do a much better job of matching phone numbers in exactly the “### ### ####” format because we define how many digits there need to be before or after each space.
Let’s take a second to break it down:
\d{3} ------- matches exactly three digits
\s ------------ matches exactly one space
\d{3} ------- matches exactly three digits
\s ------------ matches exactly one space
\d{4} ------- matches exactly four digits
But we’re just scratching the surface. What if dashes or periods were used instead of spaces?
What if the area code was wrapped in parenthesis?
What if there weren’t any spaces in the phone number?
The beauty of regex is that it is elegant enough not to matter.
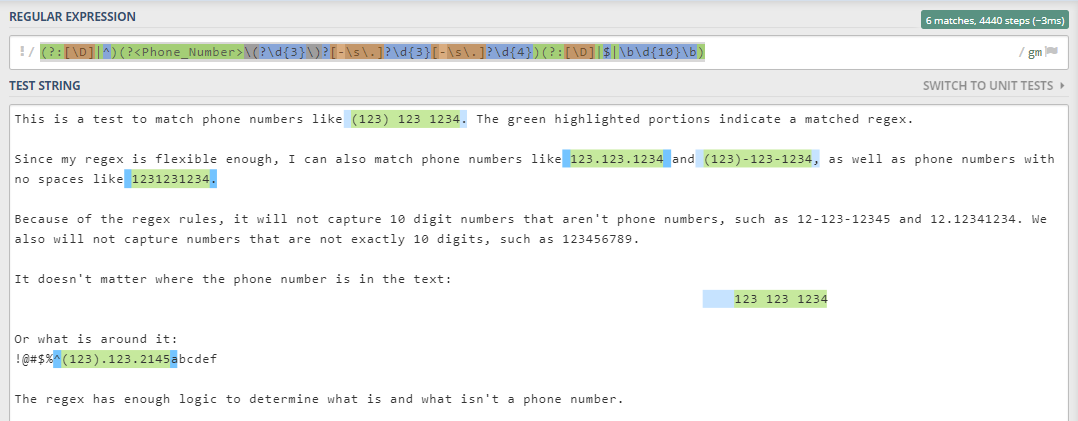
We can write a regex that takes into account all of those factors, and then have it return every instance of a phone number regardless of the format or where it is in the data source:
(?:[\D]|^)(?
I won’t break this one down since it gets into a few more advanced concepts, but I invite you to try it out for yourself https://regex101.com, which is a popular regex testing site.
Under the box labeled “REGULAR EXPRESSION”, copy and paste the regex above.
In the box labeled “TEST STRING”, type a phone number in any format that you prefer.
Assuming it’s a 10-digit phone number some type of standard format, you should see a positive match.
If you would like to know more about regex and how to use it, I would personally suggest https://regexone.com/ for a hands on approach, and https://www.regular-expressions.info/ for referencing concepts.
There are also a few text editors that permit the use of regex. The two that I use most frequently are Notepad++ (for Windows), and Sublime Text (for Linux).
On a final note, and if you’re up for a challenge, I invite you to try to figure out what the regex in the title matches (there are three main things), and how the regex works.
I will admit that I made it unnecessarily complicated and horribly inefficient in order to also challenge you to re-write the expression so that it is more efficient and precise in what it captures!
I hope you enjoyed reading my post and learned something new along the way!
